- 1. Why do you need AI red teaming?
- 2. What makes AI red teaming different from traditional red teaming?
- 3. How does AI red teaming work?
- 4. What sorts of challenges and trade-offs does AI red teaming present?
- 5. How to implement AI red teaming step-by-step
- 6. What tools are available for AI red teaming?
- 7. Real-world examples of AI red teaming
- 8. What frameworks and regulations support AI red teaming?
- 9. AI red teaming FAQs
Table of contents
- Why do you need AI red teaming?
- What makes AI red teaming different from traditional red teaming?
- How does AI red teaming work?
- What sorts of challenges and trade-offs does AI red teaming present?
- How to implement AI red teaming step-by-step
- What tools are available for AI red teaming?
- Real-world examples of AI red teaming
- What frameworks and regulations support AI red teaming?
- AI red teaming FAQs
What Is AI Red Teaming? Why You Need It and How to Implement
7 min. read
Table of contents
- Why do you need AI red teaming?
- What makes AI red teaming different from traditional red teaming?
- How does AI red teaming work?
- What sorts of challenges and trade-offs does AI red teaming present?
- How to implement AI red teaming step-by-step
- What tools are available for AI red teaming?
- Real-world examples of AI red teaming
- What frameworks and regulations support AI red teaming?
- AI red teaming FAQs

AI red teaming is a structured, adversarial testing process designed to uncover vulnerabilities in AI systems before attackers do.
It simulates real-world threats to identify flaws in models, training data, or outputs. This helps organizations strengthen AI security, reduce risk, and improve system resilience.
Why do you need AI red teaming?
AI systems are increasingly being used in high-stakes environments. That includes everything from healthcare and finance to national security. And these systems are often complex, opaque, and capable of unpredictable behavior.
"An AI red team is essential to a robust AI security framework. It ensures that AI systems are designed and developed securely, continuously tested, and fortified against evolving threats in the wild."
Which means:
They need to be tested differently than traditional software.
Red teaming gives you a way to simulate adversarial behavior. You use it to find gaps in how an AI model performs, responds, or fails. That includes AI security vulnerabilities, but also misuse risks, unfair outcomes, and dangerous edge cases.
The stakes are high. A model that seems harmless in testing could behave differently in the real world. It might respond to indirect prompts, leak sensitive data, or reinforce societal bias. Traditional testing doesn't always catch that.
That's where red teaming fits in.
"Traditional security measures, while necessary, are often insufficient to address complex LLM-specific vulnerabilities. A red team, with its holistic and adversarial approach, becomes crucial in identifying and mitigating these threats, not just through technical means but by examining the broader implications of human and organizational behaviors."
It mimics how an attacker—or just a curious user—might actually interact with the system. And it forces organizations to confront how their AI behaves under pressure.
Red teaming also helps meet regulatory and internal accountability standards. NIST and other frameworks recommend adversarial testing as part of broader AI risk management. So it's becoming a requirement, not just a best practice.
In short:
You need AI red teaming to move from theory to reality. To make sure your systems are safe, fair, and trustworthy before they're deployed at scale.
| Further reading:
- What Is Adversarial AI?
- Top GenAI Security Challenges: Risks, Issues, & Solutions
- What Is a Prompt Injection Attack? [Examples & Prevention]
- What Is a Data Poisoning Attack? [Examples & Prevention]
What makes AI red teaming different from traditional red teaming?
AI red teaming and traditional red teaming may sound similar. But they differ in important ways.
Traditional red teaming focuses on infrastructure. Think networks, servers, user accounts, physical access. The goal is to simulate real-world intrusions and test an organization's security defenses and response. It's tactical. And usually time-bound.
AI red teaming is broader. And more behavior-focused. Instead of testing access controls or firewalls, the red team probes how an AI system behaves when prompted or manipulated. That includes testing for hallucinations, prompt injection, data leakage, and misuse scenarios that are unique to machine learning.
| Traditional vs. AI red teaming at a glance | ||
|---|---|---|
| Aspect | Traditional red teaming | AI red teaming |
| Focus | Infrastructure: networks, servers, accounts, physical systems | Behavior: model responses, misuse, hallucinations, prompt manipulation |
| Techniques | Penetration testing, social engineering, physical intrusion | Adversarial prompts, data poisoning, prompt injection, model extraction |
| Attack surface | Systems and infrastructure | AI models, APIs, training data, outputs |
| Nature of testing | Deterministic—focused on access and control | Probabilistic—focused on response variability and misuse scenarios |
| Team composition | Security engineers, red teamers | Multidisciplinary: ML experts, security pros, social scientists |
| Testing goals | Exploit gaps in traditional security defenses | Identify unintended or unsafe AI behavior |
| Scope & complexity | Narrow, time-bound exercises | Broad, iterative, and evolving with the AI model lifecycle |
Why does this matter?
Because AI models don't have fixed logic like traditional software. Their outputs are probabilistic. Their training data is dynamic. And their risks—like misalignment or bias—can't always be surfaced through standard pen tests.
How does AI red teaming work?
AI red teaming is a structured way to test how an AI system might behave when exposed to adversarial input or unsafe use cases. It goes beyond scanning for bugs. Instead, it uses human-led simulations to expose vulnerabilities that automated tools often miss.
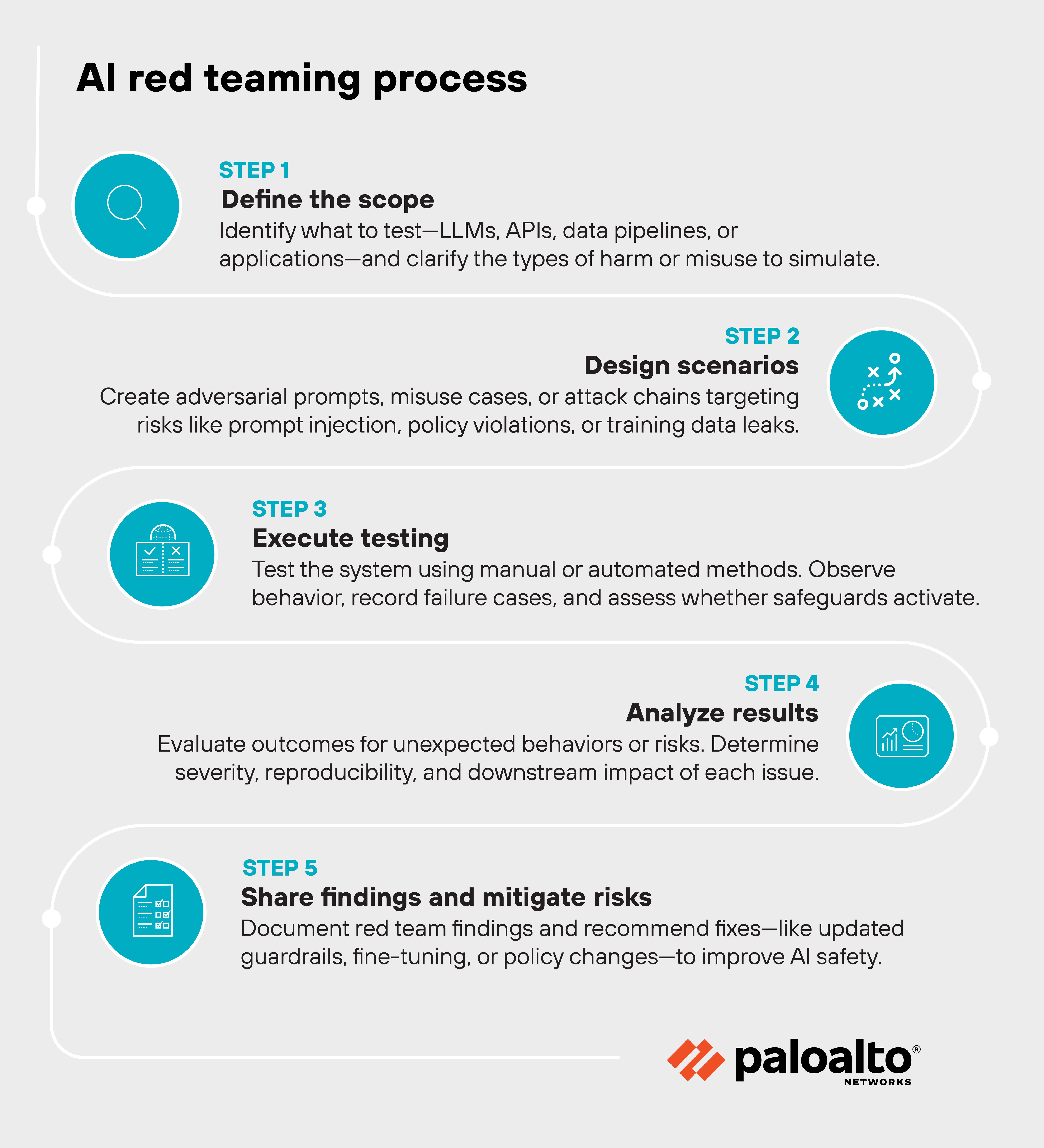
It begins with defining the scope. That might include large language models, APIs, data pipelines, or downstream applications. Teams decide what to test, which attack surfaces to target, and what types of harm or misuse they're trying to simulate.
Next comes scenario design. Red teamers craft adversarial prompts, attack chains, or misuse cases designed to expose blind spots. These might involve prompt injection, model evasion, content policy violations, or attempts to extract sensitive training data.
Execution follows. Red teamers probe the system, observe how it behaves, and record failure cases. They assess whether protections activate as intended and whether new or unexpected behaviors emerge. Some methods may be manual. Others use automated prompt generation or fine-tuned adversarial models.
Finally, findings are shared with development and risk teams. The goal is to inform mitigations—like stronger input filtering, refined fine-tuning, or policy updates—and continuously improve safety before deployment or release.
| Further reading:
Test-drive Prisma AIRS in an interactive demo and watch it uncover unsafe AI outputs in real time.
Launch demoWhat sorts of challenges and trade-offs does AI red teaming present?

AI red teaming can be incredibly effective. But it's not simple. And it's not always smooth.
For one, AI systems are probabilistic. That makes it hard to define a clear test failure. Outputs can change across identical prompts, which complicates reproducibility and undermines traditional testing baselines.
Then there's the issue of scope. LLMs are often embedded in complex applications. Is the red team targeting just the model? Or also the surrounding infrastructure, APIs, and user prompts? Clarifying this can be difficult—and leads to mismatched expectations if not agreed on early.
Another challenge is organizational. Red teams are meant to find flaws. That can create friction with development teams under pressure to ship quickly. If red teaming is introduced too late, its findings may disrupt roadmaps or generate pushback.
There are trade-offs around resources, too. AI red teaming is not cheap. It requires skilled professionals across security, ML, and human factors. And because the threat landscape is constantly changing, it's not a one-time test. It demands repeat effort and iteration.
Also important: red teams won't catch everything. Some issues—like subtle forms of model bias or poor downstream integration—may still slip through without domain-specific expertise or complementary testing methods.
In a nutshell: AI red teaming is essential. But it comes with real costs, coordination demands, and limitations. Understanding those up front helps teams plan realistically and integrate red teaming constructively.
How to implement AI red teaming step-by-step

Step 1: Define your AI red teaming objectives and scope
Start by clarifying what you're trying to learn from the red teaming exercise.
That could include uncovering prompt injection risks, evaluating model bias, or testing failure modes across scenarios.
Scope matters. Whether you're targeting the model itself, the full application stack, or surrounding infrastructure—narrowing your focus helps ensure meaningful results.
Tip:
Don't try to test everything at once. Start with a specific scenario, like jailbreaks or hallucinations. Narrow focus leads to clearer results and more actionable findings.
Step 2: Build the right team
AI red teaming is not a solo effort. You need a mix of expertise.
That usually includes machine learning specialists, security engineers, behavioral scientists, and domain experts. External partners or red team as-a-service providers can supplement internal gaps.
The key is diversity of thought and adversarial creativity.
Tip:
Brief your red team like you would a real adversary. Give them minimal context or guardrails. The goal is to simulate how an attacker would think and act. Not how a developer wants the system to behave.
Step 3: Choose attack methods and testing tools
From adversarial inputs to jailbreaking attempts, the goal is to simulate how a real-world actor might abuse the system.
Manual techniques remain essential, but red teamers often use tools to scale testing.
Open source frameworks like Microsoft's PyRIT help identify generative AI vulnerabilities and free up experts for deeper probing.
Step 4: Establish a safe testing environment
Never test against production. Create a controlled environment where teams can explore risks without unintended consequences.
That includes isolating model versions, capturing logs, and enforcing rate limits or boundaries. The safer the setup, the more aggressive and creative the testing can be.
Tip:
Log everything. Even failed attempts. They often reveal edge cases or emerging risks. Detailed logs help track prompt evolution and spot jailbreak retry patterns later.
Step 5: Analyze results and prioritize remediation
AI systems produce probabilistic outputs. So interpreting red team results often requires nuance.
You're not just logging whether an exploit succeeded. You're also assessing severity, reproducibility, and downstream impact. Use that analysis to guide remediation, guardrail updates, or risk acceptances.
Step 6: Rerun, retest, and refine
Red teaming isn't one and done. As the model, data, or app evolves, so should your tests.
Incorporate what you learn into your security practices. Build it into your SDLC.
Continuous testing is what turns red teaming from a one-off event into a foundational security discipline.
Tip:
Use model checkpoints to track behavior changes. Re-run the same red team scenarios after each update to catch regressions or new risks.
| Further reading:
- What Is AI Prompt Security? Secure Prompt Engineering Guide
- How to Build a Generative AI Security Policy
Get a personalized walkthrough of Prisma AIRS and see how continuous red teaming detects jailbreaks, leaks, and other AI risks in your environment.
Book demoWhat tools are available for AI red teaming?
The AI red teaming tool landscape is still early. There's no standard stack or dominant platform. Most of today's efforts rely on manual work supported by open source libraries, internal scripts, or extensions of existing security tooling.
That said, there are signs of movement. And a few categories of AI red teaming tools are beginning to take shape:

Some tools focus on adversarial input generation. These help simulate malicious prompts, edge cases, and evasive instructions that can bypass filters or confuse a model. They're useful for probing model robustness—but often require tuning to specific architectures or tasks.
Others support model monitoring and behavior analysis. These tools aim to capture and evaluate how models respond under stress. Some include output logging, response classification, or trigger detection to help track when a model fails or produces risky results.
You'll also see research tools designed for fairness, bias, or explainability assessments. While not always built for red teaming, they're sometimes adapted to surface unintended behaviors or edge-case harms in models under test.
The takeaway:
AI red teaming today is more of a capability than a product category. Most teams build custom workflows using lightweight tools.
But the space is evolving quickly, and some vendors are starting to package features into more complete platforms. As that happens, expect the line between red teaming and broader AI security testing to blur.
Just keep in mind—tool selection should match your model type, use case, and risk profile.
| Further reading:
See firsthand how to discover AI models, apps, and pipelines in your environment — and their risks. Book your personalized Cortex AI-SPM demo.
Request demoReal-world examples of AI red teaming
' and 'External experts, prompt risks.' The second row displays the Google logo with 'Threat-informed simulation' and 'Nation-state tactics, insider abuse.' The third row has the Microsoft logo with 'System-level attack modeling' and 'Multimodal inputs, jailbreaks.' The fourth row presents the Meta logo with 'Safety testing for open-source AI' and 'Child safety, bio threats, injection.'")
AI red teaming isn't theoretical. Leading organizations have already integrated it into their development processes to identify and reduce risk.
These examples show how red teaming is being applied at scale across different models, teams, and risk domains.
OpenAI: Combining human and automated red teaming
OpenAI uses a mix of manual, automated, and hybrid red teaming to test frontier models. The company engages external experts and internal AI systems to uncover model risks—then uses those insights to strengthen safety training and evaluation. Their recent papers formalize methods for both external expert testing and AI-assisted adversarial input generation.
Research:
Google: Aligning red teaming with threat intelligence
Google's AI Red Team simulates real-world adversaries using techniques inspired by state actors, hacktivists, and insider threats. The team conducts red team exercises across prompt injection, model extraction, data poisoning, and more. Insights from threat intelligence units like Mandiant and TAG are used to shape testing approaches and adapt to emerging attacker tactics.
Microsoft: Targeting system-level vulnerabilities
Microsoft's red teaming efforts have uncovered vulnerabilities across input types—not just text. By applying red teaming to vision-language models, the team identified weaknesses in multimodal inputs and shifted to system-level attack simulation. This helped improve model robustness and inform downstream mitigations for image-based jailbreak risks.
Meta: Red teaming in high-risk application domains
Meta uses internal and external red teaming as part of its system-level safety testing for open-source models like Llama 3.1. These efforts include adversarial evaluations for cybersecurity, prompt injection, child safety, and biological threats. The team uses insights to fine-tune safety layers, improve risk detection, and harden the model against abuse across global deployment contexts.
What frameworks and regulations support AI red teaming?
AI red teaming isn't just gaining traction among security teams. It's also being formalized in executive orders, international regulations, and risk management frameworks.
While not every rule mandates red teaming outright, the trend is clear: High-impact AI systems are expected to undergo structured adversarial testing.
| AI red teaming references in major regulations and frameworks | ||
|---|---|---|
| Regulation or framework | Relevance to AI red teaming | Notes |
| U.S. Executive Order on AI (2023) | Calls for red teaming of dual-use foundation models | Sections 4.1 and 10.1 reference both internal and external testing requirements for generative AI |
| NIST AI Risk Management Framework | Encourages adversarial testing as part of securing AI systems | Red teaming isn't named directly, but threats like prompt injection and model exfiltration are covered under resilience guidance |
| EU AI Act (2024) | Requires adversarial testing for high-risk models before market release | Focuses on model evaluations, including red teaming, as part of risk mitigation |
| Google's Secure AI Framework (SAIF) | Explicitly promotes red teaming and adversarial testing | Section on 'Secure development' advises organizations to test models using adversarial input to detect unsafe behaviors |
| Further reading:
-
What Is AI Governance?
- NIST AI Risk Management Framework (AI RMF)
- Google's Secure AI Framework (SAIF)
Pinpoint AI adoption risks before red teaming begins with Unit 42's AI Security Assessment.
Learn moreAI red teaming FAQs
AI red teaming is a structured process that simulates adversarial behavior to uncover vulnerabilities in AI systems, models, or outputs before real-world attackers do.
Red teaming is the practice of emulating threats to test system resilience. In AI, it focuses on probing model behavior, misuse scenarios, and failure modes—not just traditional security controls.
AI teaming refers to human-AI collaboration, where AI systems work alongside people to support decision-making or task execution. It's common in defense, healthcare, and enterprise settings. Unlike red teaming, AI teaming is cooperative, not adversarial.
Red teaming in constitutional AI involves adversarial testing to evaluate whether a model consistently follows a set of predefined ethical principles or behavioral rules—known as its “constitution.” The goal is to uncover misalignment, harmful outputs, or loopholes in rule-following.