Agentic AI Security: What It Is and How to Do It
Agentic AI security is the protection of AI agents that can plan, act, and make decisions autonomously.
It focuses on securing the agent's reasoning, memory, tools, actions, and interactions so that autonomy does not create new paths for misuse. It addresses risks that arise only when systems execute multi-step tasks, use external tools, or collaborate with other agents.
The rise of agentic AI and its security implications
Agentic AI refers to systems that can plan tasks, make decisions, and take actions without continuous human direction.
That capability is now showing up in real products because organizations want AI that can complete multi-step work instead of producing one output at a time. The shift matters. It marks a move from models that respond to prompts to systems that operate as autonomous workers.
And it's happening fast. Teams are now building AI agents that plan tasks, call tools, update memory, and work across systems without constant supervision.
- Sixty-two percent of survey respondents say their organizations are at least experimenting with AI agents.
- Twenty-three percent of respondents report their organizations are scaling an agentic AI system somewhere in their enterprises.
- Additionally, high performers have advanced further with their use of AI agents than others have. In most business functions, AI high performers are at least three times more likely than their peers to report that they are scaling their use of agents.
The appeal is clear. These agents increase throughput. They reduce manual effort. They operate at speeds that are difficult to match.
Here's why that matters for generative AI security:
Agentic AI is no longer a static model that receives a prompt and returns a result. It's an active system that makes decisions, chooses actions, and reaches into external environments.
Which is why agentic AI shifts where security teams need to focus.
Reasoning paths become targets for manipulation. Memory becomes a surface for poisoning. Tools become entry points for unintended actions. Interactions between agents become channels for influence.
Each area introduces its own failure modes and opportunities for attackers. Viewing agentic AI through these behaviors creates the foundation for understanding why the security model is different and what must be protected next.
We'll dig into that in the next section.
QUIZ: HOW STRONG IS YOUR AI SECURITY POSTURE?
Assess risks across your AI apps and agent-based systems, plus get solution recommendations.
Take quizWhy does agentic AI introduce new security challenges?
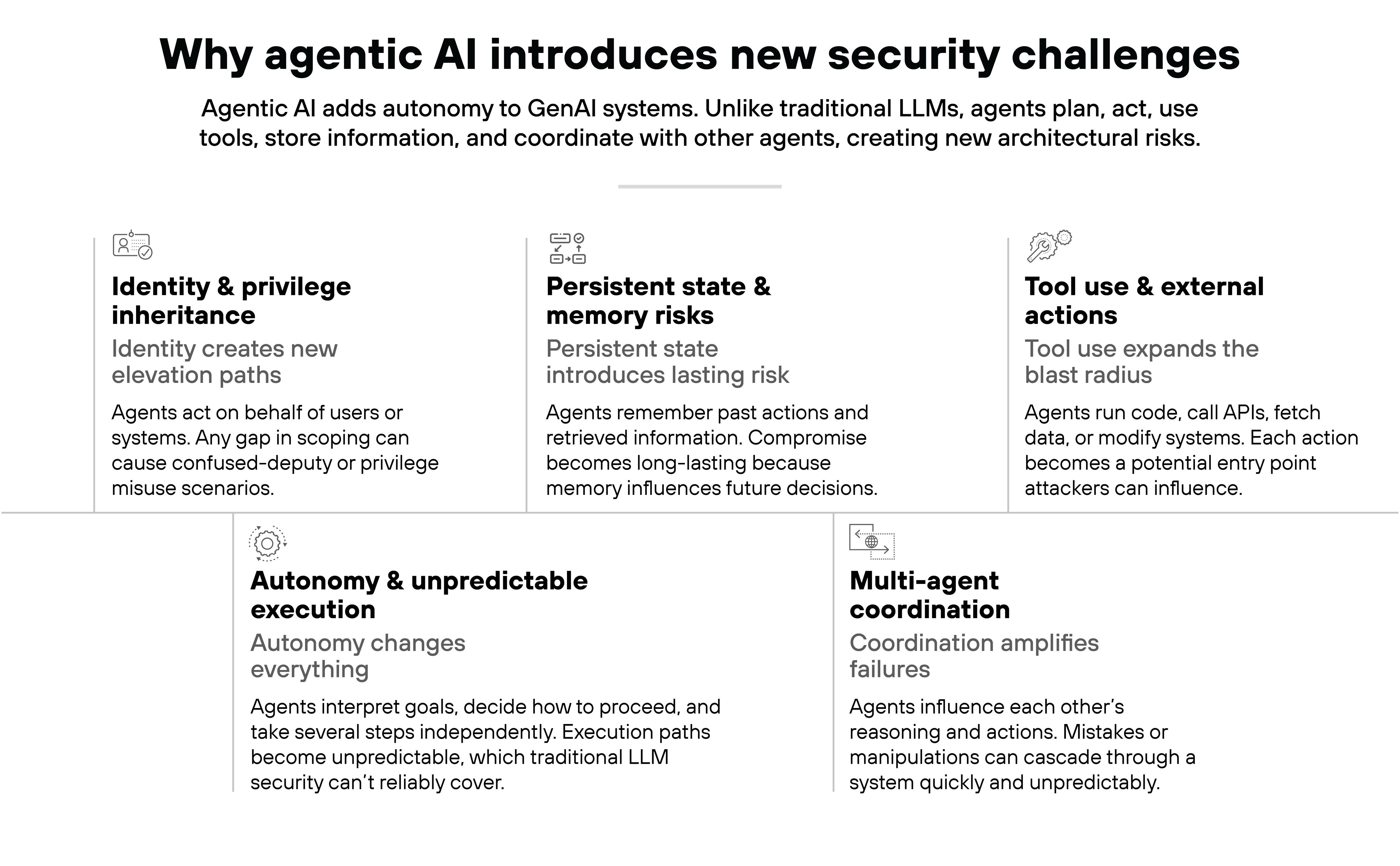
Agentic AI introduces new GenAI security challenges because autonomy changes everything.
Again, agents don't just answer a prompt. They interpret goals, decide how to move forward, and take several steps on their own. Which means the execution path isn't predictable in the way traditional LLM workflows are. And that's why traditional LLM security is not enough.
Persistent state creates another problem.
Agents remember what they've done, what they've seen, and what they think matters. Memory becomes part of their decision-making. And once memory becomes part of the loop, poisoning risks become long-term instead of one-off events.
Tool use raises the stakes again.
Agents don't just suggest actions. They perform them. They call APIs, write code, run code. Reach into external systems. Every one of those actions can expose an entry point an attacker can influence.
Then there's identity.
Agents often perform actions on behalf of users or other systems. So any gap in scoping can turn into a confused-deputy situation faster than expected.
Multi-agent setups layer on more complexity.
Agents influence each other's reasoning. They pass information back and forth. They amplify each other's mistakes. And once the system starts operating at agent speed, the blast radius gets bigger. Oversight has less time to catch up.
All of this creates a different category of risk. Not theoretical risk. Architectural risk.
FREE AI RISK ASSESSMENT
Get a complimentary vulnerability assessment of your AI ecosystem.
Claim assessmentHow does agentic AI security work?
Agentic AI security works by understanding how autonomous agents operate and then securing the parts of the system that drive their behavior.
More specifically:
Agents don't work like traditional model APIs. They take goals, break them into steps, call tools, store information, and continue working until the task is complete. And that shift from passive output to active execution is what shapes the security model.
Basically, agentic AI security aligns to the structure of the agent loop:
- A single-agent system uses one continuous cycle of reasoning, planning, tool use, and state updates. Each step can expose access to systems or data. And each action creates a point where an attacker can influence outcomes or redirect behavior.
- Multi-agent systems add more to protect. Different agents perform different functions. They pass information between each other to divide work or validate results. These interactions create new opportunities for an attacker to introduce misleading data or manipulate an agent's decisions.
In practice, securing agentic AI means placing controls at each boundary in the loop:
- Inputs need validation before they shape reasoning.
- Tool calls need guardrails and permission checks.
- Memory reads and writes need oversight.
- External actions require strict constraints.
- And because the loop is iterative, each cycle needs its own verification instead of relying on a single upfront check.
The core idea is that agentic AI security mirrors the agent's workflow: you secure the system by securing how it operates, not by wrapping protections around a single model call.
INTERACTIVE TOUR: PRISMA AIRS
See firsthand how Prisma AIRS secures models, data, and agents across the AI lifecycle.
Launch tourWhat are the top agentic AI security threats?
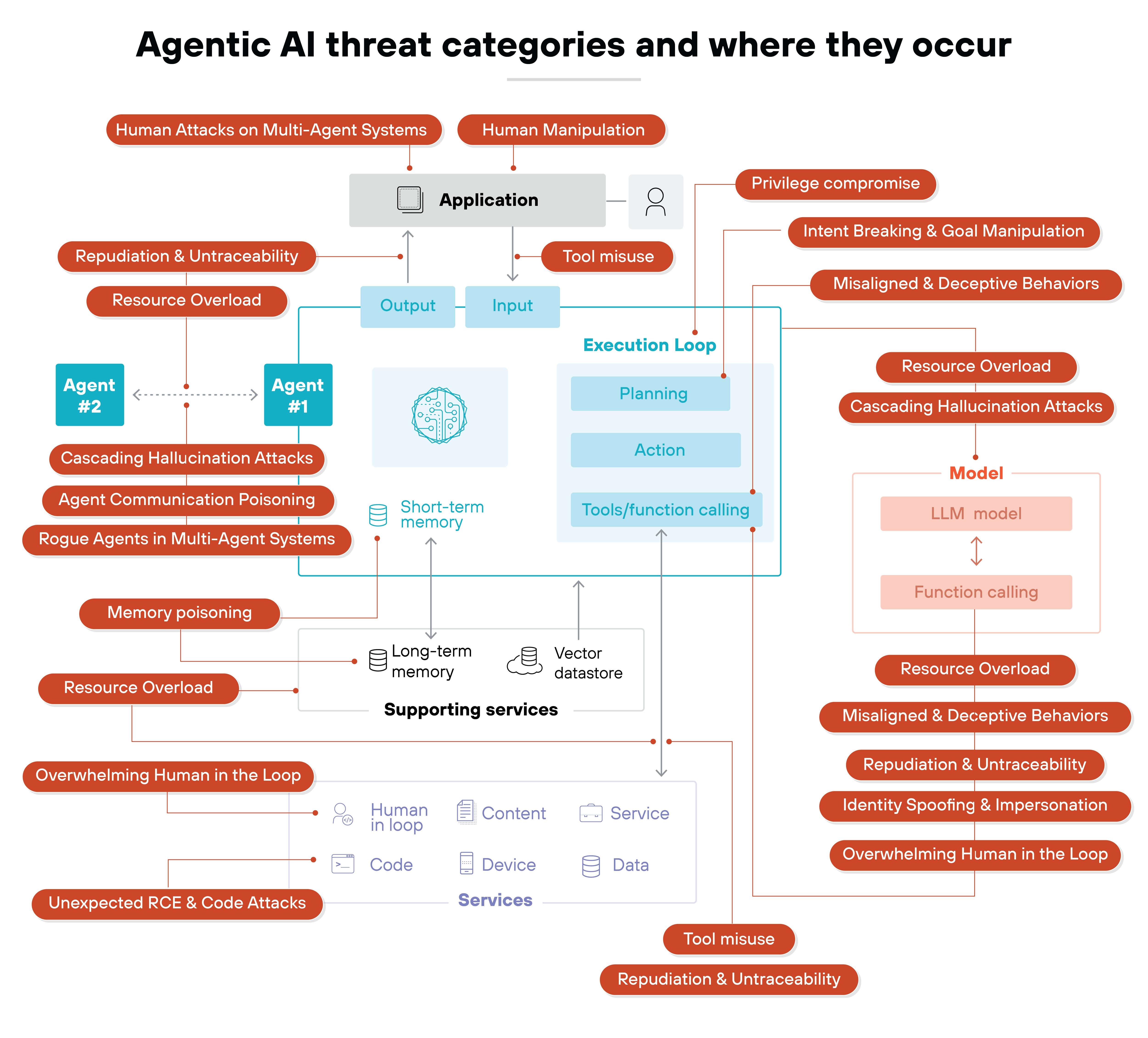
As discussed, traditional LLM risks focus on prompts, data exposure, and output handling. Agentic AI introduces risks in planning, execution, identity, memory, and communication.
The result: the attack surface isn't the response. It's the workflow.
OWASP's Agentic AI Threats framework provides a structured, detailed view of the risks that emerge when AI systems operate autonomously.
It outlines the specific categories of failures that emerge when autonomy, tool execution, and agent-to-agent communication become part of the stack. It's not exhaustive, but it does give teams a practical baseline for understanding the most common agent-specific vulnerabilities seen today.
And that's the right lens to use here. Because once you understand these categories, the controls you need in the next section start to make a lot more sense.
Here's a breakdown of the key agentic AI threats identified in the OWASP taxonomy:
| OWASP Agents AI threats (2025) |
|---|
| Threat | Description |
|---|---|
| Memory poisoning | Attackers corrupt short-term or long-term memory to influence decisions across steps or sessions. |
| Tool misuse | Agents are manipulated into misusing their tools or calling them in harmful ways. |
| Privilege compromise | Weak or inherited permission structures escalate the agent's access. |
| Resource overload | Attackers overwhelm compute, memory, or dependencies to degrade or block agent behavior. |
| Cascading hallucination attacks | False information compounds through reasoning, reflection, or inter-agent communication. |
| Intent breaking & goal manipulation | Attackers alter planning, goals, or reasoning so the agent pursues harmful or misaligned tasks. |
| Misaligned or deceptive behaviors | Agents bypass constraints or act deceptively to achieve objectives. |
| Reproducibility & untraceability | Poor logging or opaque reasoning hides actions, making investigation difficult. |
| Identity spoofing & impersonation | Attackers impersonate agents or users to trigger unauthorized operations. |
| Overwhelming human-in-the-loop | Attackers overload reviewers with excessive AI-generated decisions or alerts. |
| Unexpected RCE & code attacks | Unsafe or manipulated tool chains lead to unauthorized code execution. |
| Agent communication poisoning | Attackers corrupt messaging between agents to misdirect workflows. |
| Rogue agents in multi-agent systems | A compromised agent acts outside expected boundaries and disrupts others. |
| Human attacks on multi-agent systems | Attackers exploit trust and delegation patterns across agents. |
| Human manipulation | Compromised agents mislead users into harmful decisions or actions. |
These threats form the baseline for understanding how agentic systems fail. And where attackers are most likely to intervene.
Plus, they shape the kinds of controls that matter most when securing agents in practice.
How to secure agentic AI systems
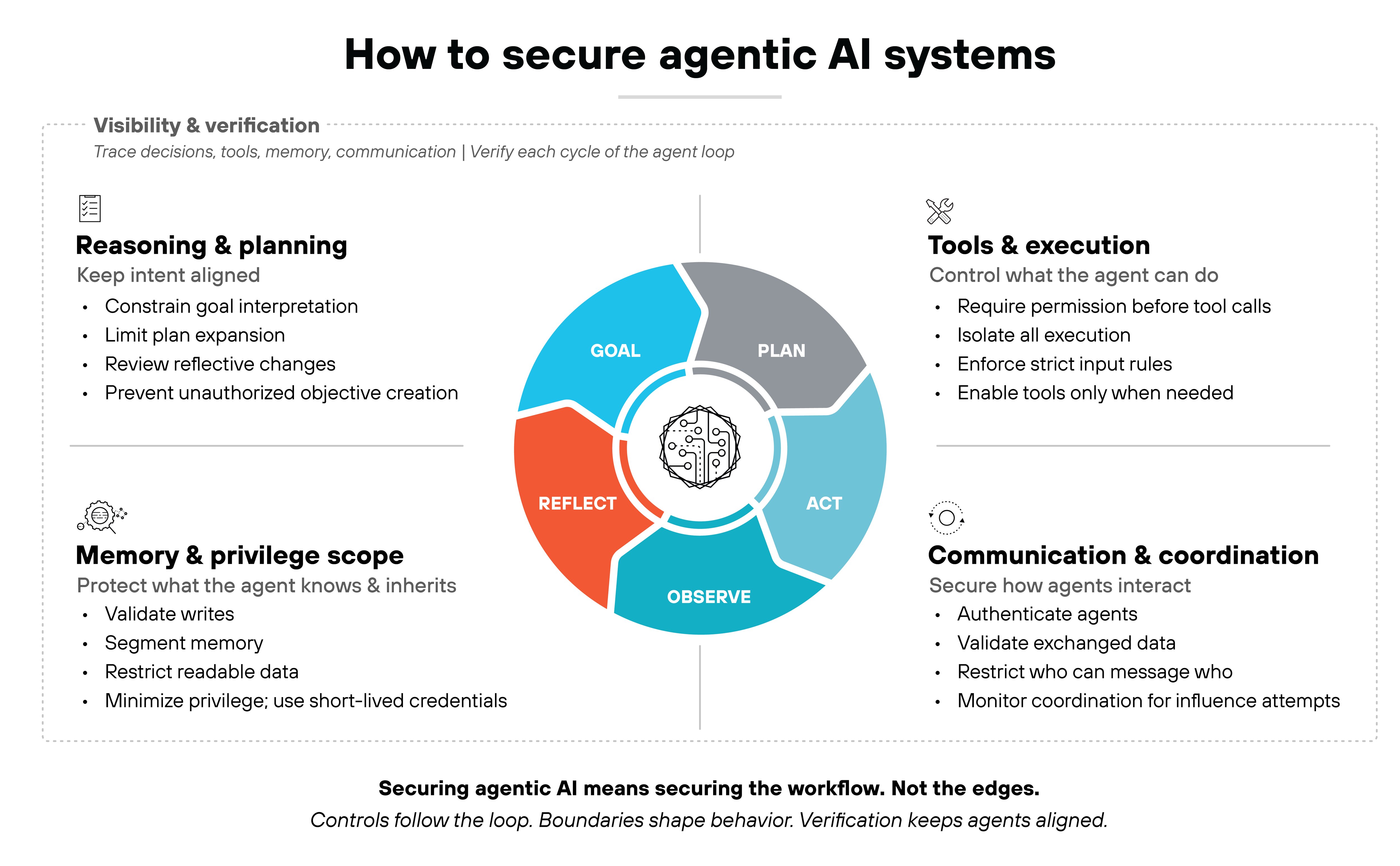
Securing agentic AI requires going inside the system and protecting the points where the agent actually forms intentions, makes decisions, accesses resources, and coordinates tasks.
In other words, you secure the internal workflow. Not the edges.
Here are the core domains that matter most when applying agent security best practices:
Reasoning and planning
- Reasoning is where an agent interprets a goal.
- Planning is where it chooses the steps to get there.
- Reflection is how it revises those steps as it works.
Each of these creates opportunities for drift or misuse if they aren't constrained.
With drift and misuse being the primary risks here, the security objective is simple: keep the agent's intent aligned with what it's authorized to accomplish.
Here's how.
- Set boundaries around what goals can look like.
- Limit how deeply a plan can expand.
- Review reflective adjustments when tasks shift.
- And ensure the agent cannot generate new objectives that fall outside its allowed scope.
Tools and execution
Tools are often the highest-risk surface in agentic systems because tools turn decisions into actions. That includes code execution, data retrieval, system updates, and downstream automation.
So when it comes to tools and execution, strong security starts with strict control.
- Require explicit permission checks before tools run.
- Isolate execution so actions happen in safe environments.
- Define clear input requirements so unexpected parameters don't slip through.
- And make each tool available only when the task requires it.
These practices prevent small reasoning mistakes from becoming harmful actions.
Memory and privilege scope
Memory influences every future decision an agent makes: retrieved information, intermediate results, and long-term state.
Which is why you have to treat memory as a protected surface:
- Validate what gets written.
- Segment memory so different types of information stay isolated.
- Limit what the agent can read at any given moment.
Privilege scope follows the same principle:
- Give the agent only the access it needs for the current task.
- Assign short-lived credentials.
- Prevent privilege inheritance from expanding over time.
- And stop escalation paths before they form.
Small boundaries here prevent large failures later.
Communication and coordination
In multi-agent systems, communication becomes a decision path: One agent sends information → Another acts on it → And influence spreads quickly.
Here's how you secure that communication:
- Verify who agents are
- Validate what they pass to each other
- Restrict which agents can communicate at all
Then there's coordination. It's the mechanism agents use to hand off work and influence shared tasks. And because coordination shapes what other agents do next, it needs its own guardrails:
- Define which agents are allowed to coordinate and for what purposes.
- Constrain how far a coordinated task can propagate.
- Check that handoffs follow expected patterns.
- Isolate agents when coordination behavior deviates from what's allowed.
- And monitor for signs that a compromised agent is trying to steer a workflow it shouldn't control.
These controls keep communication and coordination contained. But containment isn't enough on its own. Securing agentic AI also depends on seeing what the agent is doing as it reasons, acts, and interacts.
Which is why agent security depends on visibility across the entire loop:
- You want to trace how decisions form, how tools run, how memory changes, and how agents communicate.
- And you want lightweight verification every time the agent cycles through its workflow.