- 1. What do people really mean by 'black box AI' today?
- 2. Why do today's AI models become black boxes in the first place?
- 3. Why is the black box problem getting worse now?
- 4. What problems does black box AI actually cause in the real world?
- 5. How black box systems fail under the hood
- 6. How to reduce black box risk in practice
- 7. Where AI explainability actually helps (and where it doesn't)
- 8. What's next for managing black box AI?
- 9. Black box AI FAQs
Table of contents
- What do people really mean by 'black box AI' today?
- Why do today's AI models become black boxes in the first place?
- Why is the black box problem getting worse now?
- What problems does black box AI actually cause in the real world?
- How black box systems fail under the hood
- How to reduce black box risk in practice
- Where AI explainability actually helps (and where it doesn't)
- What's next for managing black box AI?
- Black box AI FAQs
Black Box AI: Problems, Security Implications, & Solutions
6 min. read
Table of contents
- What do people really mean by 'black box AI' today?
- Why do today's AI models become black boxes in the first place?
- Why is the black box problem getting worse now?
- What problems does black box AI actually cause in the real world?
- How black box systems fail under the hood
- How to reduce black box risk in practice
- Where AI explainability actually helps (and where it doesn't)
- What's next for managing black box AI?
- Black box AI FAQs
Black box AI refers to systems whose internal reasoning is hidden, making it unclear how they convert inputs into outputs.
Their behavior emerges from high-dimensional representations that even experts can't easily inspect. This opacity makes trust, debugging, and governance harder. Especially when models drift, confabulate, or behave unpredictably under real-world conditions.
What do people really mean by 'black box AI' today?

Black box AI used to mean a model that hid its internal logic behind layers of statistical relationships.
That definition came from classical machine learning. And it made sense when models were smaller and easier to reason about.
But that framing no longer fits modern AI systems. And that's because opacity—the inability to see how models reach their conclusions—looks very different now.
Deep learning models rely on high-dimensional representations that even experts struggle to interpret. Large language models (LLM) add another layer of complexity because their reasoning paths shift based on subtle changes in prompts or context. Agents go further by taking actions, using tools, and making decisions with internal state that organizations often cannot observe.
Which means:
Black box behavior is no longer only an interpretability problem.
It's a security issue. And a reliability issue. And a governance issue.

You can't validate a model's reasoning when its internal mechanisms are hidden. You can't audit how it reached a decision. And you can't detect when its behavior changes in ways that affect safety, oversight, or compliance.
That's why understanding black box AI today requires a broader, more modern view of how opaque these systems have become.
Why do today's AI models become black boxes in the first place?

AI models seem harder to understand today because their internal representations no longer map cleanly to concepts humans can interpret.
Early systems exposed features or rules. You could often see what influenced a prediction. But that's no longer how these models work.
Deep learning systems operate in high-dimensional spaces.
In other words, they encode patterns across thousands of parameters that interact in ways humans can't easily disentangle. Neurons carry overlapping roles. Features blend together. And behavior emerges from the combined activity of many components rather than any single part
Example:
An LLM asked to 'explain quantum physics to a child' doesn't flip a single 'simplify' switch. Instead, tone, structure, and vocabulary emerge from many interacting components adjusting to context. There's no single part you can point to that causes the shift.
Large language models introduce even more opacity.
Their outputs depend on subtle prompt changes and shifting context windows. Which means their reasoning path can vary even when the task looks the same. Instruction tuning and reinforcement techniques add another layer of uncertainty because they reshape behavior without exposing how that behavior changed internally.
Example:
An LLM that once responded directly may begin answering more cautiously after instruction tuning. The behavioral shift comes from thousands of preference adjustments diffused across the model, not from any identifiable change in a specific component.
Retrieval-augmented generation (RAG) pipelines and agentic systems compound the problem.
They retrieve information. They run tools. They maintain state. And they make decisions that organizations may not be able to observe directly.
All of this creates models that are powerful but difficult to inspect.
It also explains why black box behavior is a structural property of today's AI systems rather than a simple interpretability gap.
| Further reading:
- AI Model Security: What It Is and How to Implement It
- What Is LLM (Large Language Model) Security? | Starter Guide
- Agentic AI Security: What It Is and How to Do It
- Top GenAI Security Challenges: Risks, Issues, & Solutions
Why is the black box problem getting worse now?
According to McKinsey's survey, The state of AI in 2025: Agents, innovation, and transformation:
- 88% of survey respondents report regular AI use in at least one business function
- 62% say their organizations are at least experimenting with AI agents, while 23% percent of respondents report their organizations are scaling an agentic AI system somewhere in their enterprises
- 51% of respondents from organizations using AI say their organizations have seen at least one instance of a negative consequence, most commonly inaccuracy and explainability failures
- Yet explainability—while a top risk experienced—is not one of the most commonly mitigated risks
AI models aren't just getting bigger. They're becoming harder to observe and explain. That's not just a scale problem. It's a structural one.
Small models used to rely on limited features and straightforward patterns. But foundation models encode behavior across billions of parameters. Which means their reasoning becomes harder to trace. Even subtle updates to training data or prompt structure can change how they respond.
Then come the agents.
Modern AI systems now take actions. They use tools. They maintain memory. And they perform multi-step reasoning outside of what's visible to the user. Each decision depends on the internal state. And that state isn't always observable or testable.
Retrieval-augmented pipelines add more complexity.
They shift control to the model by letting it decide what external knowledge to pull in. That retrieval process is often invisible. And organizations may not realize what information is influencing outputs.
The rise of proprietary training pipelines is another driver.
Without transparency into data sources, objectives, or fine-tuning methods, downstream users are left with a model they can't verify or validate.
And regulators have noticed.
Recent frameworks increasingly emphasize explainability, auditability, and risk documentation. Which means the expectations are going up. Right when visibility is going down.
PERSONALIZED DEMO: CORTEX AI-SPM
Schedule a personalized demo to experience how Cortex AI-SPM maps model risk, data exposure, and agent behavior.
Book demoWhat problems does black box AI actually cause in the real world?

Black box AI doesn't just make model behavior harder to understand. It makes the consequences of that behavior harder to predict, trace, or fix. And those consequences show up in ways that matter to reliability, safety, and security.
Opaque reasoning creates hallucinations and unstable logic paths.
LLMs can return answers that look confident but have no factual grounding. That includes fabricated citations, flawed reasoning, and incomplete steps. Which means users might act on something false without knowing it's wrong.
Hidden failure modes stem from shortcut learning and spurious cues.
Some models perform well in testing but fail in the real world. Why? Because they learn to exploit irrelevant patterns like background artifacts or formatting instead of the task itself. These weaknesses are often invisible until deployment.
Security exposure increases when behavior is untraceable.
Black box models can be poisoned during training. Or manipulated through prompts. Or misaligned in how they use tools and make decisions. That opens the door to jailbreaks, data leakage, or even malicious agent behavior.
Audit and compliance break down without transparency.
You can't validate how a model made a decision if you can't see what influenced it. That creates challenges for documentation, oversight, and meeting regulatory expectations around AI accountability.
Operational fragility rises when debugging is impossible.
Drift becomes harder to detect. Outputs vary unexpectedly. And organizations struggle to identify root causes when something goes wrong. That limits their ability to correct, retrain, or regain control.
Essentially, black box AI creates risks at every level of the AI lifecycle. And those risks are harder to manage when visibility is low.
| Further reading:
- What Are AI Hallucinations? [+ Protection Tips]
- What Is AI Bias? Causes, Types, & Real-World Impacts
- What Is Data Poisoning? [Examples & Prevention]
- What Is a Prompt Injection Attack? [Examples & Prevention]
Free AI risk assessment
Get a complimentary vulnerability assessment of your AI ecosystem.
Claim assessmentHow black box systems fail under the hood
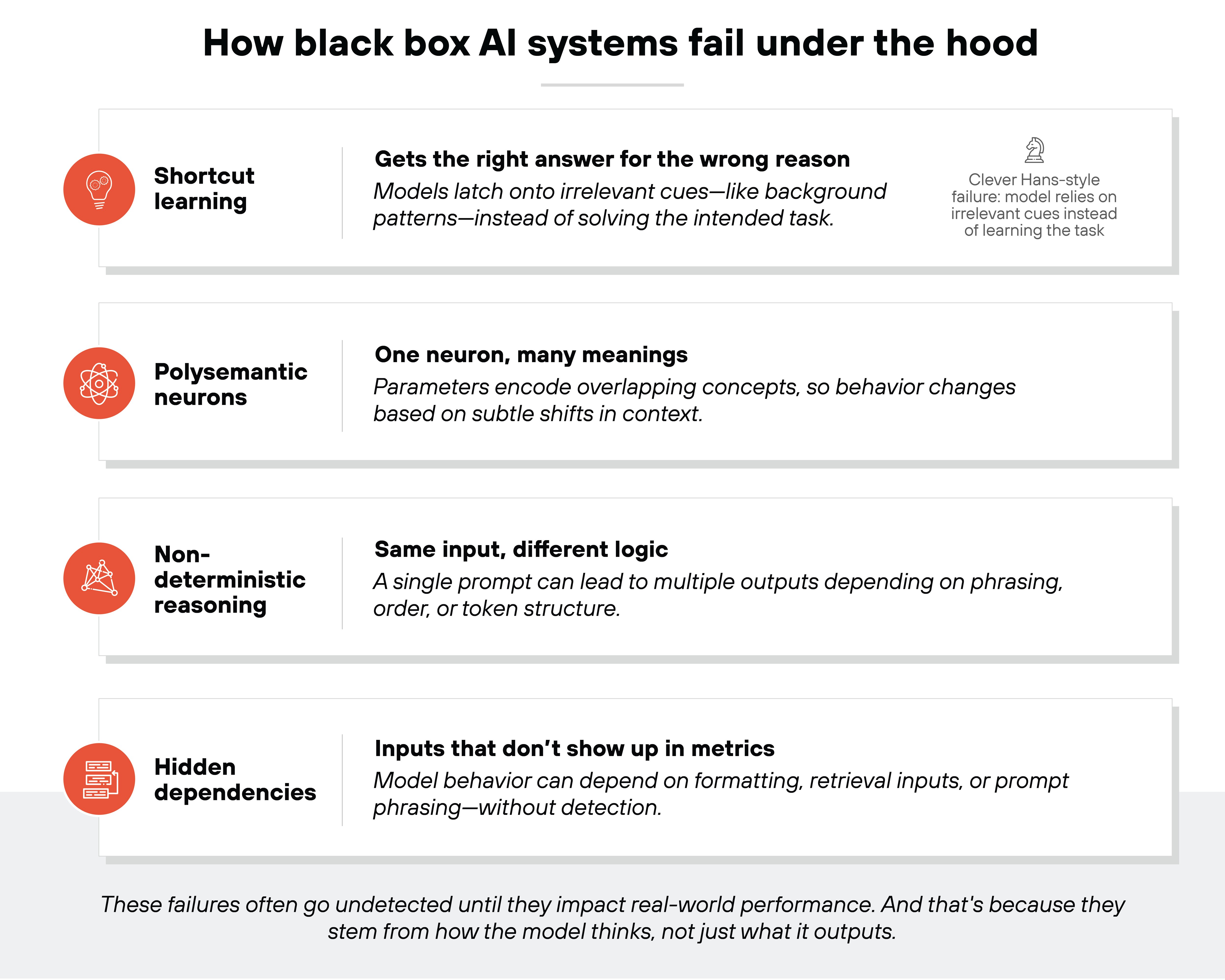
Black box AI systems don't just produce unpredictable results. They fail in ways that are hard to detect, and even harder to explain.
Here's what that failure looks like when you trace it back to the model's internals:
Some models get the right answer for the wrong reasons.
That's shortcut learning. The model might rely on irrelevant background cues or formatting artifacts instead of learning the task.
These Clever Hans-style failures (named after a horse that appeared to do math but was actually reading subtle human cues) often go unnoticed during evaluation and surface only after deployment.
Other models show signs of entangled internal structure.
That's because deep models encode multiple features into the same parameters.
Polysemantic neurons fold several unrelated patterns into the same unit. The same neuron might activate for both a shape in an image and a grammatical pattern in text. That shifting role makes it impossible to interpret what an activation ‘means.'
LLMs also show non-deterministic reasoning paths.
The same prompt can produce different responses based on prompt order, structure, or tiny variations in wording. In other words, the model's logic isn't fixed. It shifts with context.
Then there are hidden dependencies.
That includes formatting, instruction phrasing, or retrieval inputs. These variables shape how the model performs. But they don't show up in evaluation metrics.
All of this makes failure hard to catch. Especially when the underlying behavior can't be easily inspected.
How to reduce black box risk in practice
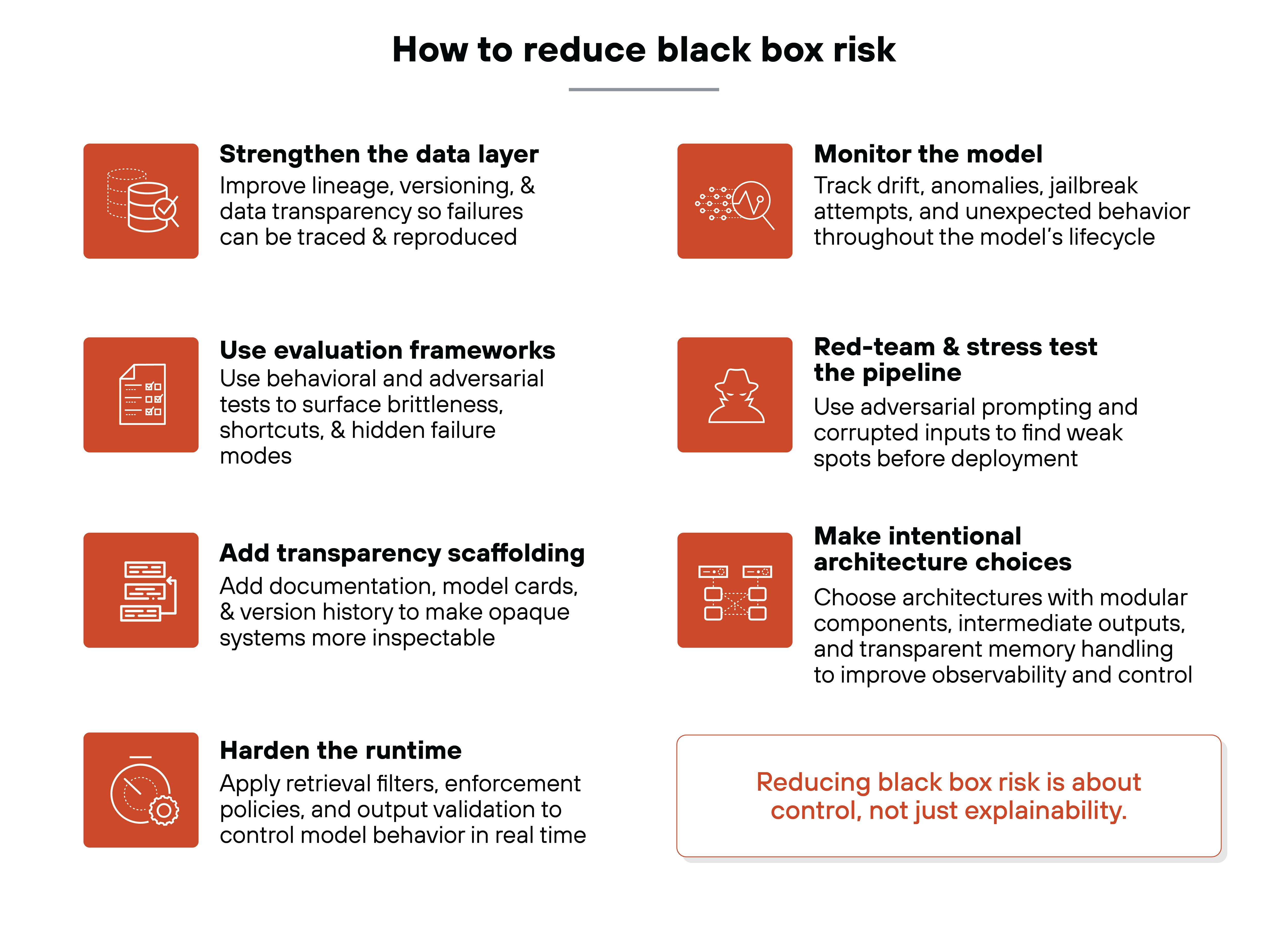
Reducing black box AI risk isn't just about making models explainable. It's about putting real-world controls in place that help organizations see, test, and manage opaque behavior across the lifecycle.
This starts before training. And it continues long after deployment.
Here's what that looks like in practice:
Strengthen the data layer
Black box AI problems often begin with poor data governance. That includes unclear lineage, undocumented transformations, and missing provenance.
When training data isn't well defined or versioned, failures are harder to trace and fix. So the model might be doing the wrong thing for reasons no one can reconstruct.
Data transparency is the foundation for downstream visibility and explainability.
Use evaluation frameworks
Standard model metrics don't reveal much about how a model thinks. That's why behavioral and adversarial testing is essential.
These methods simulate failure scenarios and test for brittleness, bias, or reliance on spurious patterns. Without them, many shortcut-driven failures won't surface until deployment. And at that point, the cost of fixing them goes up.
Add transparency scaffolding
Models don't explain themselves. But organizations can add scaffolding that makes them easier to understand and govern.
That includes documentation, model cards, version history, and intermediate reasoning traces. This won't make a black box model interpretable. But it does make it more inspectable.
And it supports oversight, even when internals can't be fully decoded.
Harden the runtime
Black box AI solutions shouldn't rely solely on training-time fixes.
Runtime guardrails reduce the risk of unsafe or non-compliant behavior. That includes retrieval filters, policy enforcement, output validation, and safety layers.
These systems don't explain the model. But they help control what gets through. And stop what shouldn't.
Monitor the model
Opacity makes ongoing monitoring critical.
Models can drift, degrade, or start behaving unexpectedly. But without visibility, those changes go unnoticed.
Monitoring tools should flag jailbreak attempts, prompt anomalies, or behavioral drift. This is especially important for systems that interact with users or external tools.
Red-team and stress test the pipeline
Explainable AI isn't enough.
Organizations need to probe their models the way attackers or auditors would. That includes adversarial prompting, corrupted retrieval inputs, or supply-chain manipulation.
The goal is to uncover weak spots before deployment. And to understand how models behave under pressure.
| Further reading: What Is AI Red Teaming? Why You Need It and How to Implement
Make intentional architecture choices
Architecture plays a big role in interpretability.
That means choosing systems with intermediate outputs, isolatable components, and transparent memory handling. Agents and retrieval pipelines should be broken into modules with clear boundaries.
Like this, organizations can observe, control, and debug more of the process. Even when the model itself remains a black box.
INTERACTIVE TOUR: PRISMA AIRS
See firsthand how Prisma AIRS secures models, data, and agents across the AI lifecycle.
Launch tourWhere AI explainability actually helps (and where it doesn't)
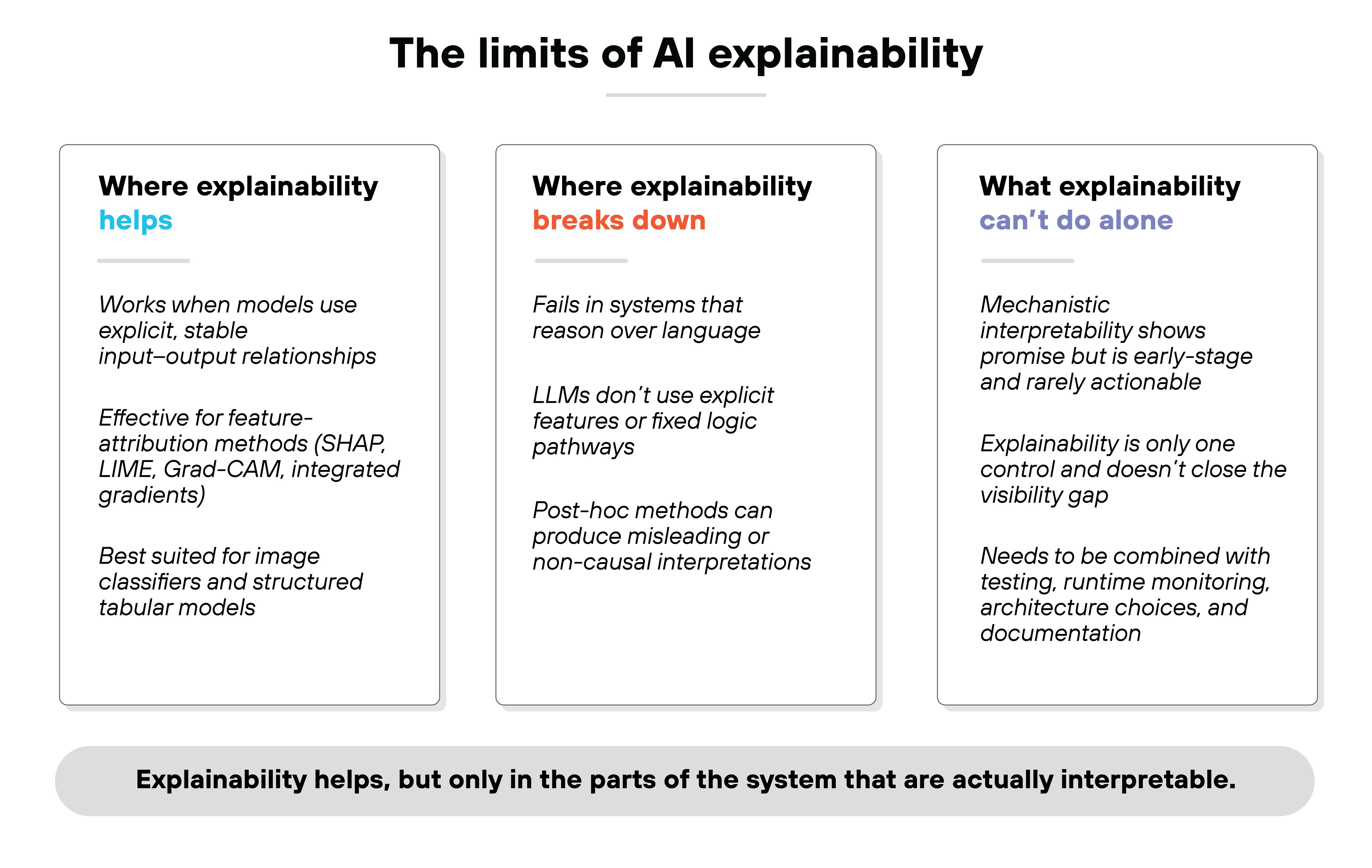
AI explainability refers to techniques that help people understand why a model produced a particular output.
Different methods try to expose which inputs or patterns influenced a decision. But they only work when those patterns are represented in ways humans can interpret.
Explainability helps when it aligns with how the model represents information.
That includes feature-attribution methods like SHAP, LIME, Grad-CAM, or integrated gradients. These techniques are useful for models with clearly defined input-output relationships. Like image classifiers. Or models with structured tabular inputs.
But it breaks down in systems that reason over language.
LLMs don't use explicit features. Their logic shifts across context windows, token positions, and sampling temperatures. Which means post-hoc methods can mislead users into thinking they understand something that isn't actually interpretable.
Mechanistic interpretability offers another path.
It aims to reverse-engineer circuits or neuron roles in deep networks. That work has shown promise. Especially in cases like induction heads or attention pattern tracing. But the field is early. And the insights are rarely actionable for enterprise teams working with commercial models.
Important:
Explainability alone won't close the visibility gap.
It's just one control. And it works best when combined with testing, runtime monitoring, architecture choices, and documentation. That's how organizations start to manage the risks of black box AI in practice.
| Further reading: What Is Explainable AI (XAI)?
What's next for managing black box AI?
Visibility is no longer a feature you bolt on.
It's a system property. And it only works when built across the full lifecycle, from data design to model outputs.
Here's why that shift matters:
Security, reliability, and trustworthiness all depend on being able to observe how AI systems behave. You can't mitigate what you can't monitor. And you can't govern what you can't trace.
So where should organizations start?
With transparency scaffolding. Monitoring. Policy enforcement. Evaluation. Controls that reduce uncertainty—even when they don't fully explain the model.
Research is moving fast.
Mechanistic interpretability is uncovering new structures. Evaluation benchmarks are improving. And governance frameworks like AI TRiSM are beginning to reflect how fragmented, opaque systems actually work.
In the end, managing black box AI doesn't mean decoding every layer.
It means designing systems that stay visible, accountable, and aligned. Even when full interpretability isn't possible.
| Further reading:
Personalized demo: Prisma AIRS
Schedule a personalized demo with a specialist to see how Prisma AIRS protects your AI models.
Book demoBlack box AI FAQs
A black box AI system is one whose internal logic, representations, or decision processes are not understandable to humans, even when inputs and outputs are known.
Deep models encode information in high-dimensional spaces across many layers and parameters, making it difficult to trace how inputs lead to outputs or which features drive predictions.
Yes, especially in high-stakes domains. Black box AI can fail in ways that are hard to detect or explain, increasing risks around safety, fairness, and accountability.
Not fully. But we can use post hoc explanation tools, architectural choices, and runtime controls to improve visibility into black box behavior and reduce risk.
Interpretable models (like decision trees or linear models) show how inputs relate to outputs. Black box models (like deep neural networks) obscure that reasoning and require external tools to analyze decisions.
Yes. LLMs do not rely on explicit features or rules. Their responses emerge from distributed patterns across tokens, weights, and context windows, making their reasoning opaque.
Because deep models use overlapping, polysemantic representations. Their behavior arises from the combined activity of many components, not a single traceable rule or path.
Common tools include SHAP, LIME, Grad-CAM, and Integrated Gradients. These provide post hoc approximations of model behavior but can be misleading if the model’s structure doesn’t support interpretation.
Only with additional controls. Organizations must apply explainability techniques, auditing frameworks, runtime safeguards, and monitoring to meet compliance and safety standards.
Failures include biased medical diagnoses, incorrect credit scoring, or AI models relying on irrelevant features like background artifacts known as shortcut learning.