AI applications and agents are seeing widespread adoption in enterprises across industries. In finance, AI is uncovering fraud in real-time and shutting it down before the damage spreads. In healthcare, it’s predicting diseases earlier and more accurately, giving patients a better chance at treatment and recovery. In consulting, it’s compressing what used to be months of research into days or even hours.
But every organization leveraging these capabilities to build powerful experiences for their customers is concerned about whether these experiences are secure enough. To build powerful systems, executive leadership needs to understand why these modern AI systems need a different approach to security.
The New Frontier of Risk: Why AI Demands a Different Security Mindset
The "Unknown Unknowns" of AI
While organizations are increasingly deploying AI, they lack visibility into novel attack vectors specific to AI/ML models (e.g., adversarial attacks, data poisoning, prompt injection, model inversion, fairness/bias exploits). Traditional security testing, such as regular penetration testing or vulnerability scanning, is often static, focuses on known vulnerabilities and struggles to keep pace with the dynamic, opaque, and constantly evolving nature of AI systems. This leaves valuable intellectual property, sensitive data and business processes exposed to exploitation and manipulation, hindering secure AI adoption.
Need to Continuously Assess the Safety and Security Posture
Unlike traditional software where minor updates usually have predictable impacts, even small, seemingly innocuous changes to an AI model (e.g., fine-tuning with new data, minor architectural tweaks, hyperparameter adjustments) can have unforeseen and significant negative consequences on its safety, security and ethical behavior. Organizations lack a reliable, scalable mechanism to continuously validate the security and safety posture of their AI models through their entire lifecycle, especially during iterative development. This leads to lack of confidence in enterprises around deploying AI systems on production.
Inefficient and Incomplete Manual Red Teaming
AI models are stochastic in nature. While enterprises recognize the value of red teaming, performing it manually, especially for complex AI systems, is incredibly time-consuming time and resource-intensive, requiring highly specialized and expensive talent. Human red teams can't address the stochastic nature of AI, leading to infrequent testing, limited scope and potential blind spots. Manual red teaming is thus not comprehensive and too resource-intensive, making it nonviable to continuously do it as part of the AI development cycle progresses. There are no means to continuously identify and address key risk areas in AI models and applications powered by those models.
The Broadening Attack Surface and Real-World Urgency of AI Threats
The evidence is overwhelming. Earlier this year, researchers conducted a massive public red teaming competition with 1.8 million prompt injection attempts against AI agents. Over 60,000 attacks successfully bypassed safeguards, and most models failed after fewer than a hundred queries. That shows how easily even sophisticated systems can be compromised. Anthropic confirmed recently that its Claude model had already been weaponized for fraud, ransomware and extortion campaigns. They have dedicated research teams trying to prevent Claude from being used in cybercrime.
AI Red Teaming Delivers Insights with Efficiency
The whole attack surface is shifting faster than traditional tools can keep up. Runtime checks are one of the solutions to keep your systems secure, but they are not enough as a singular solution. It’s been observed, time and again, that pre-runtime evaluation can find these same issues when they are exponentially cheaper and easier to fix, helping protect revenue and reputation from costly post-deployment failures.
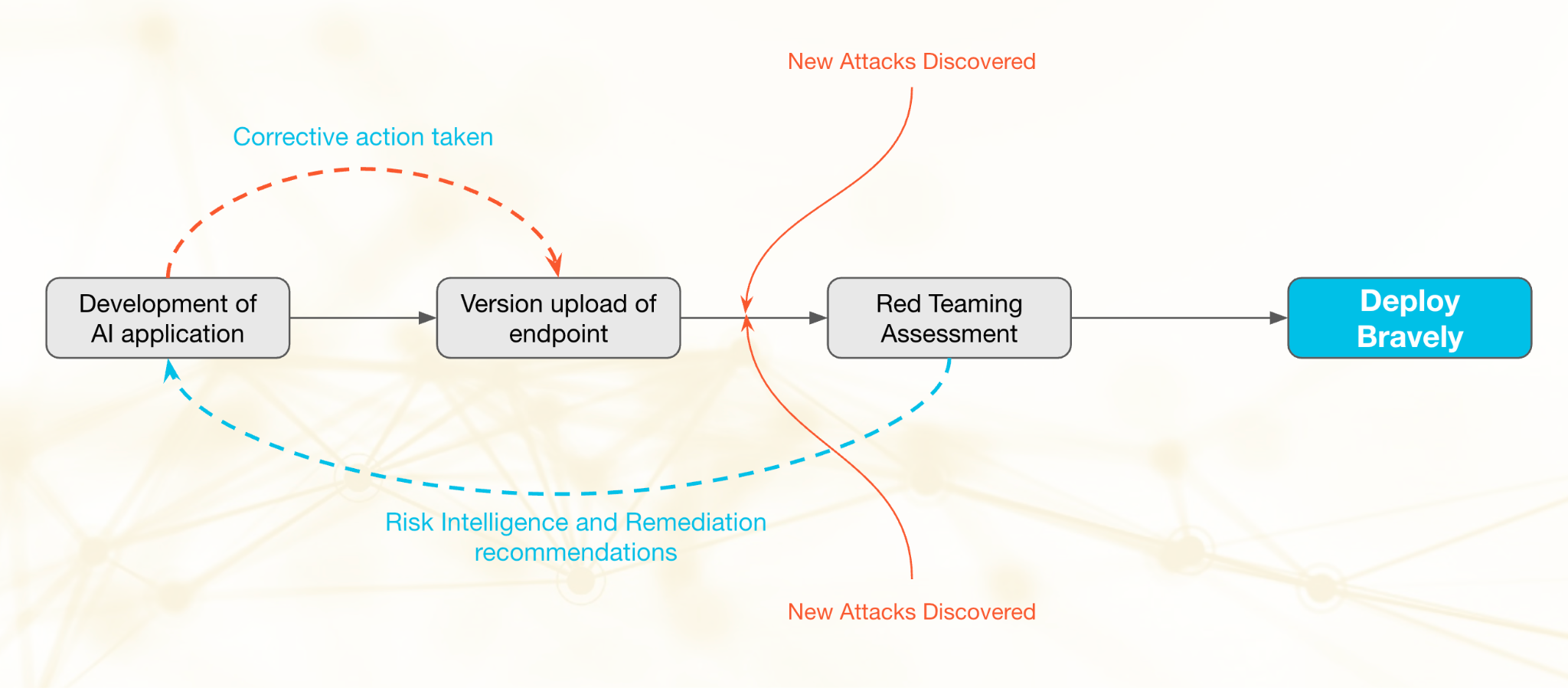
What Constitutes Good AI Red Teaming?
Think of AI red teaming as continuous structured adversarial testing conducted pre-runtime on AI applications and agents. A good AI red teaming campaign designs and executes scenarios where the objective is to break the AI system and get it to either say something bad or act wrongly. That would include crafting prompts to bypass guardrails, probing for data leaks, testing whether an AI agent can be tricked into misusing tools, or simulating denial-of-service through resource-heavy inputs.
A good red teaming isn’t a one-off exercise; it must be performed continuously, preferably after every change to your application to evaluate any change in security alignment. Remember, we are dealing with non-deterministic systems. The cause and effect of a change on security is not formulated yet. With continuous red teaming, you gain insights into where your weak spots are, and how you can fix them.
Red teaming has always been a cybersecurity practice. Because natural language has now become the new weapon of choice, the need for AI red teaming is higher than ever. The cost of not red teaming will essentially be borne by the runtime element and by then it’s late. Runtime breaches can expose sensitive data, inflate compute costs, and damage trust with regulators, boards and customers. Moreover, your security operations will be overloaded since the new weapon of choice is simple language. Continuous red teaming helps you stay ahead of the attackers.
Your Leadership Checklist: Three Critical Questions
If you are an executive in an organization walking into a steering committee meeting or a board meeting, you should be asking these three questions:
- Are we testing our AI security continuously?
- Are we testing across all AI assets (models, applications and agents)?
- Are we aligning our findings with compliance frameworks?
AI red teaming makes failure a drill, so that you can avoid a crisis.
That’s why Palo Alto Networks built AI red teaming directly into PrismaⓇ AIRS. It is continuous, scenario-driven adversarial testing. Prisma AIRS simulates real-world attack patterns, maps them to frameworks like OWASP’s LLM Top 10 and MITRE ATLAS, and provides actionable recommendations. Imagine if a red teaming insight can auto-configure your AI runtime security policies. It will let you sleep peacefully at night and let you deploy with absolute confidence. It empowers your organization by removing guesswork in this new world.
Continuously red team your AI applications. Deploy Bravely.